|
The hidden reality of AI-Driven development (Sponsored)
 |
There is a new “velocity tax” in software development. As AI adoption grows, your teams aren’t necessarily working less—they are spending 25% of their week fixing and securing AI-generated code. This hidden cost creates a verification bottleneck that stalls innovation. Sonar provides the automated, trusted analysis needed to bridge the gap between AI speed and production-grade quality.
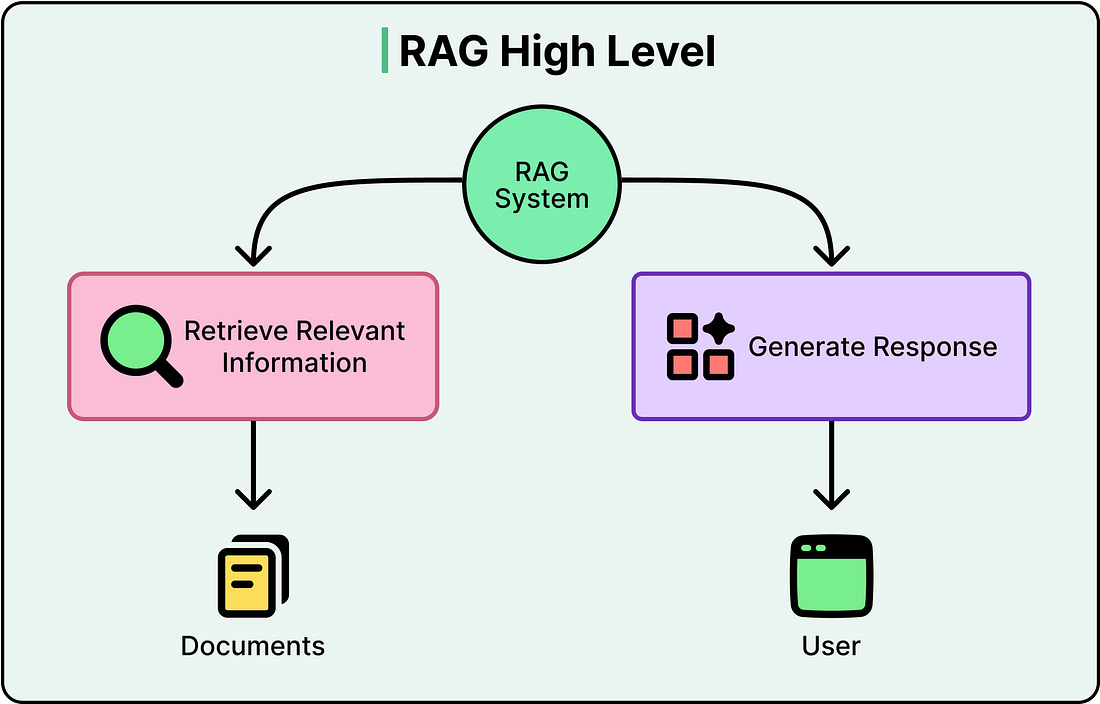
The main problem with standard RAG systems isn’t the retrieval or the generation. It’s that nothing sits in the middle deciding whether the retrieval was actually good enough before the generation happens.
Standard RAG is a pipeline where information flows in one direction, from query to retrieval to response, with no checkpoint and no second chance. This works fine for simple questions with obvious answers.
However, the moment a query gets ambiguous, or the answer is spread across multiple documents, or the first retrieval pulls back something that looks good but isn’t, RAG starts losing value.
Agentic RAG attempts to fix this problem. It is based on a single question: what if the system could pause and think before answering?
In this article, we will look at how agentic RAG works, how it improves upon standard RAG, and the trade-offs that should be considered.
 |
One Query and One Retrieval
To understand what Agentic RAG fixes, we need to be clear about how standard RAG works and where it falls short.
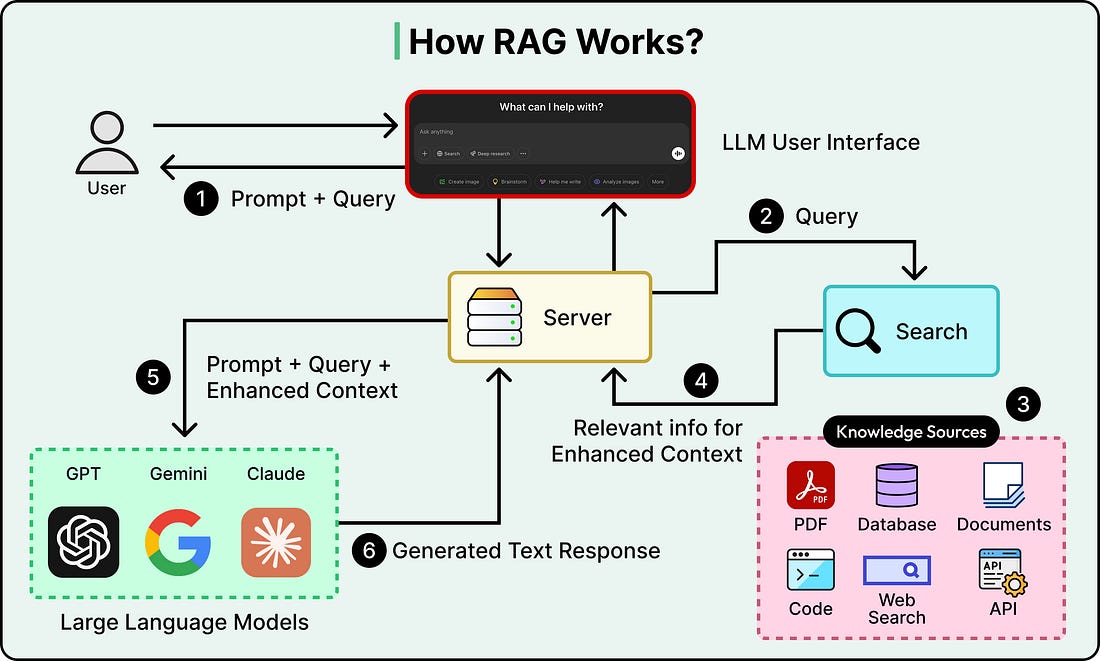
A standard RAG pipeline has a straightforward flow:
A user asks a question.
The system converts that question into a numerical representation called an embedding, which captures the semantic meaning of the query.
It then searches a vector database, a database optimized for finding content with similar meaning, and retrieves the top matching chunks of text.
Those chunks get passed to a large language model along with the original question, and the LLM generates an answer grounded in the retrieved context.
See the diagram below:
 |
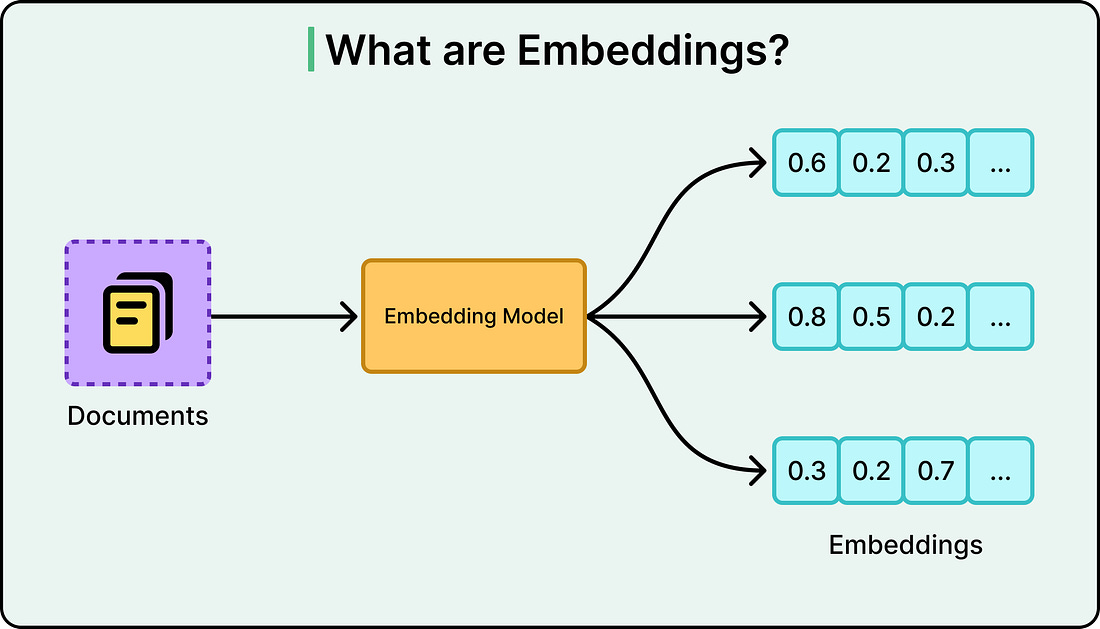
The diagram below shows what embeddings typically look like:
 |
This works extremely well for direct and unambiguous questions against a well-organized knowledge base. Think of questions like “What’s our return policy?” A clean documentation corpus will get a solid answer almost every time.
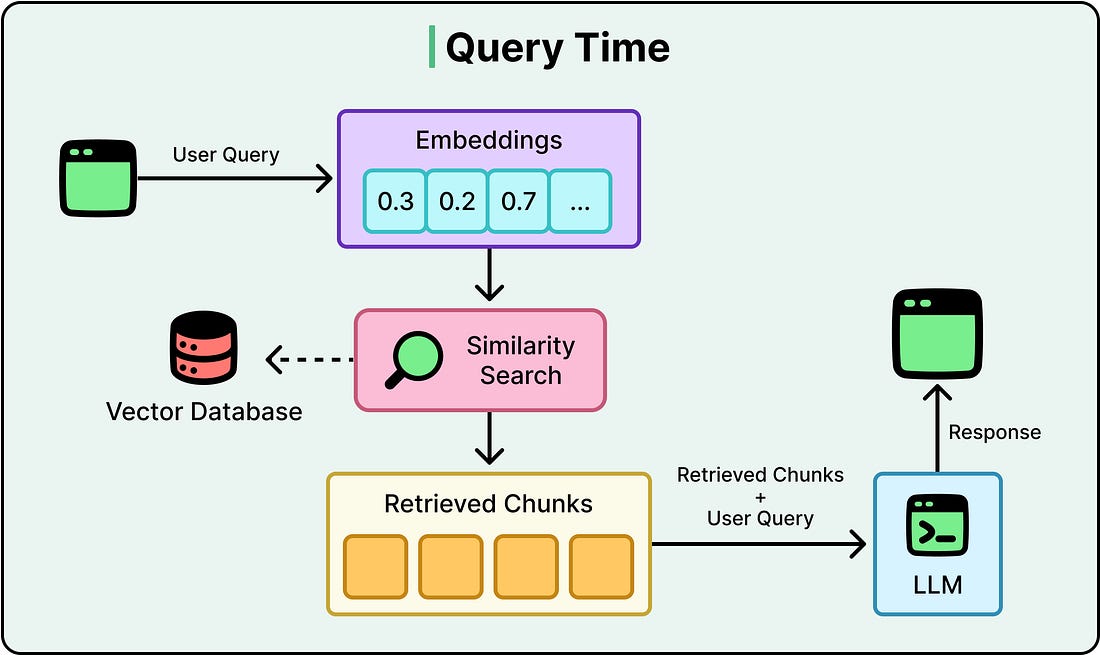
Here’s how typical query flow looks like:
 |
The problems show up when queries get more complex. Here are a few scenarios: