|
 |
NVIDIA Advances Its Open-Model Strategy with Nemotron 3
Plus: OpenAI introduced GPT-5.2-Codex, Gemini 3 Flash gets faster and cheaper, and Z.ai’s GLM-4.7 tops open-source AI.
Hello Engineering Leaders and AI Enthusiasts!
This newsletter brings you the latest AI updates in just 4 minutes! Dive in for a quick summary of everything important that happened in AI over the last week.
And a huge shoutout to our amazing readers. We appreciate you😊
In today’s edition:
🚀 NVIDIA debuts Nemotron 3 family of open models
🔒 OpenAI launches GPT-5.2-Codex for secure coding
⚡ Google bets on speed with Gemini 3 Flash
🏆 Z.ai’s GLM-4.7 tops open-source coding AI
🧠 Zoom’s AI beats Gemini on tough reasoning test
💡Knowledge Nugget: AI Is Causing Layoffs, Just Not in the Way You Think by Eric Lamb
Let’s go!
NVIDIA debuts Nemotron 3 family of open models
NVIDIA introduced Nemotron 3, a new family of open models built specifically for multi-agent systems, marking its most serious move yet into large-scale model development. The lineup includes Nano (30B), Super (100B), and Ultra (500B), with Nano already available and larger versions expected in 2026. NVIDIA says Nano beats similar-sized models on coding and instruction-following while running more than three times faster.
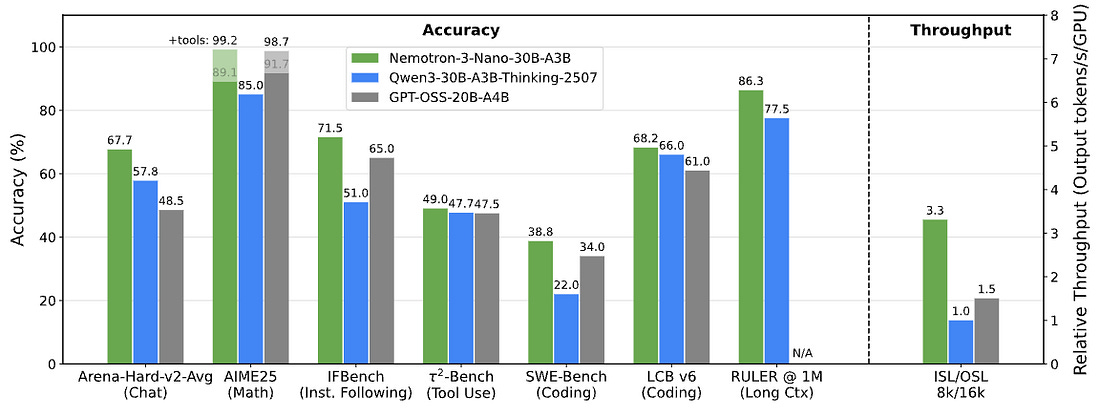 |
NVIDIA is also publishing training data, fine-tuning tools, and reinforcement learning environments alongside the models. Companies like Cursor, Perplexity, ServiceNow, and CrowdStrike are already using Nemotron 3 across coding, search, enterprise automation, and cybersecurity.
Why does it matter?
With many Western AI labs doubling down on closed ecosystems and in-house chips, open model momentum has drifted outside the U.S. NVIDIA reshapes that balance, giving developers a credible open option while keeping advanced AI workloads closely tied to NVIDIA’s platform.
OpenAI launches GPT-5.2-Codex for secure coding
OpenAI introduced GPT-5.2-Codex, a coding-focused version of GPT-5.2 designed for real-world software engineering and cybersecurity work. The new model is tuned for long-running tasks like refactors, migrations, and debugging across large repositories, using native context compaction to hold onto critical details over hours of autonomous work.
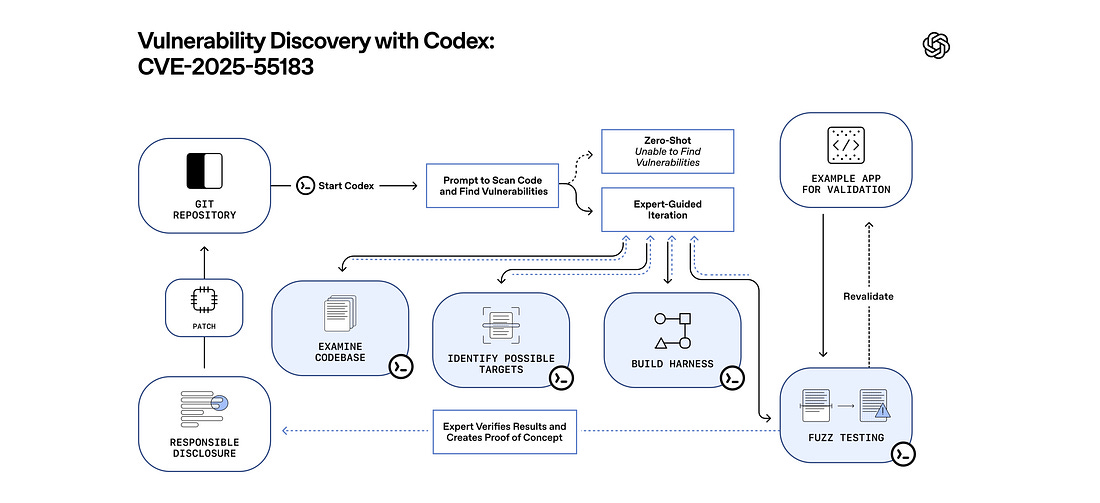 |
OpenAI says GPT-5.2-Codex posts state-of-the-art results on developer benchmarks like SWE-Bench Pro and Terminal-Bench, with improvements aimed at practical reliability rather than flashy demos.
Why does it matter?
This is OpenAI quietly admitting that chatbots were the warm-up act. The real payoff is coding agents that can work for hours without losing context. If this holds up in practice, it shifts AI value from clever demos to systems that actually replace chunks of day-to-day engineering work.
Google’s Gemini 3 Flash gets faster and cheaper
Google rolled out Gemini 3 Flash, a speed-focused version of its flagship model that still holds up on frontier benchmarks. Flash runs three times faster than Gemini 3 Pro, costs a quarter as much, and matches or beats Pro across several reasoning and coding tests.
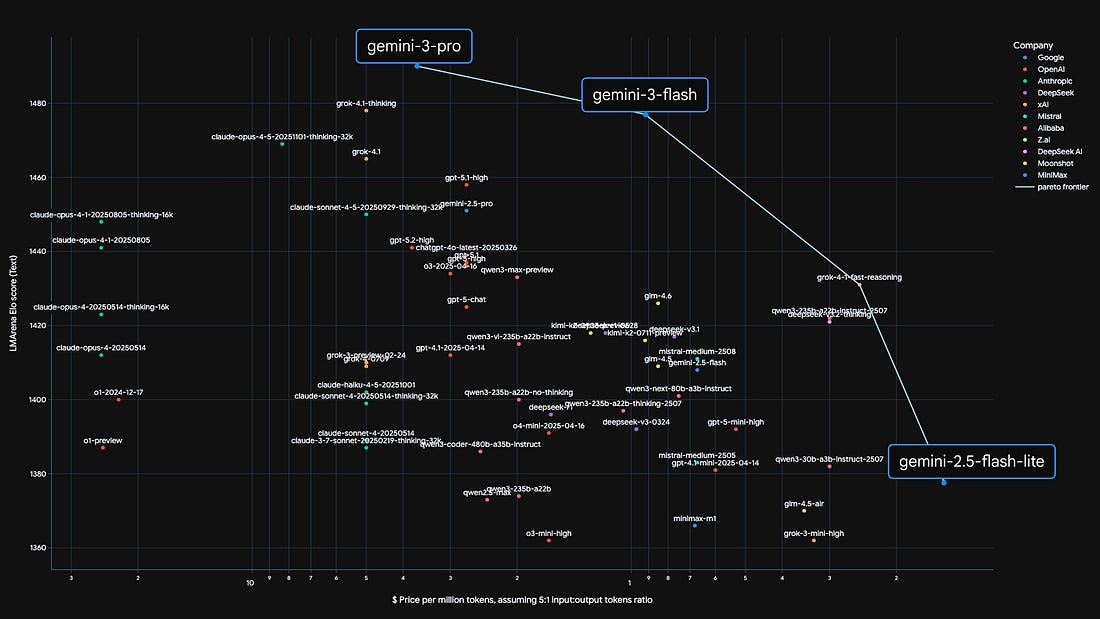 |
Google has already made Flash the default model across the Gemini app and Search’s AI Mode. On Humanity’s Last Exam, Flash scored 33.7%, nearly on par with GPT-5.2, signaling that faster, cheaper models are closing the gap with top-tier reasoning systems.
Why does it matter?
Somehow, the faster model ends up being the more important release. By pairing strong reasoning with low latency and aggressive pricing, Gemini 3 Flash makes high-end AI far easier to use at scale and gives Google another lever to steadily chip away at OpenAI’s lead in everyday AI workflows.
Z.ai’s GLM-4.7 tops open-source coding AI
Z.ai, a Chinese AI startup, released GLM-4.7, an open-source coding model that posted a 73.8% score on SWE-Bench, setting a new high for open systems. That result puts it ahead of rivals like DeepSeek-V3.2 and Kimi K2, and in striking distance of top Western coding models.